-
MySQL 실험: 공간 인덱스 Optimizer 동작 분석 & 성능 실험Database 2025. 9. 4. 22:22
공간인덱스를 안 타네? Optimizer가 의도한대로 동작했습니다.
Overview
API 성능 로그를 보다가, 특정 테이블에서
ST_Intersects쿼리만 유독 느린 걸 발견했습니다.A 테이블 (약 1.2만 rows) → 인덱스 사용
B 테이블 (약 56만 rows) → 인덱스 사용
R 테이블 (약 8.3만 rows) → 인덱스 무시 + 풀스캔 발생 🤔인덱스도 정상인데 왜
R 테이블만 풀스캔일까?Optimizer가 cost를 어떻게 계산하는지 직접 확인해보기로 하고 실험을 설계했습니다.
실험 방법
실험환경
- DBMS: MySQL 5.7.40
- Geometry: POINT 타입
- 테이블 3종 세트 준비
I TABLE: 공간 인덱스 강제 (FORCE INDEX)F TABLE: 인덱스 없음(풀스캔)O TABLE: Optimizer 판단
그리고 row 수를 1천 단위로 늘려가면서
EXPLAIN FORMAT=JSON으로 cost 값을 추출 및 결과를 시각화했습니다.
Cost 측정
Cost 측정은
EXPLAIN FORMAT=JSON결과에서query_cost,read_cost,eval_cost,prefix_cost를 파싱하는 방식으로 수행했습니다.def explainCost(tbl, isIndex=False): """ tbl: 인덱스 있는 테이블명 또는 없는 테이블명 (prefix) isIndex: True면 FORCE INDEX(coords) 강제 """ index = "FORCE INDEX(coords)" if isIndex else "" query = f""" EXPLAIN FORMAT=JSON SELECT * FROM {tbl}_test {index} WHERE ST_WITHIN( coords, ENVELOPE(LINESTRING( POINT(127.01851232809271, 37.484408149821725), POINT(127.04121239101583, 37.502418909010125) )) ) """ cursor = execute(query) row = cursor.fetchone()[0].replace("\n", "") d = json.loads(row) return { "cost": d["query_block"]["cost_info"]["query_cost"], "read_cost": d["query_block"]["table"]["cost_info"]["read_cost"], "eval_cost": d["query_block"]["table"]["cost_info"]["eval_cost"], "prefix_cost": d["query_block"]["table"]["cost_info"]["prefix_cost"], }
실험결과
전체 COST 비교
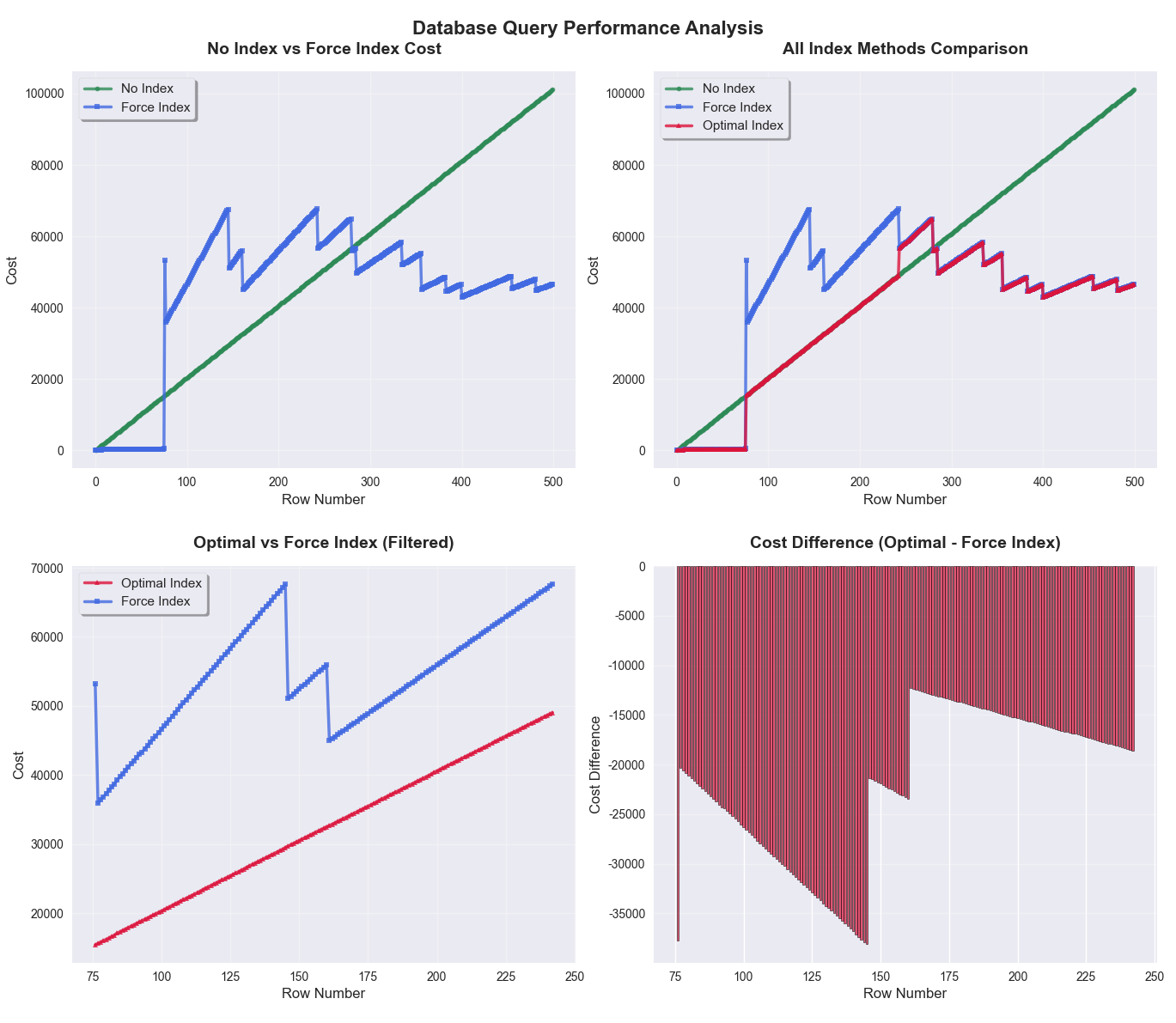
결과를 보니 아주 흥미로운 패턴이 있었습니다
- 약 7.7만 ~ 25만 rows 구간에서
Optimizer가 풀스캔을 선택 - 그 외 구간에서는 공간 인덱스를 사용
실제 서비스에서 문제가 된 R 테이블(≈ 8.3만 rows)이 딱 이 구간에 들어가 있었음!!
즉,
Optimizer입장에서는 특정 구간에서 인덱스보다 풀스캔이 cost 상 더 유리하다고 판단!
세부 COST 비교
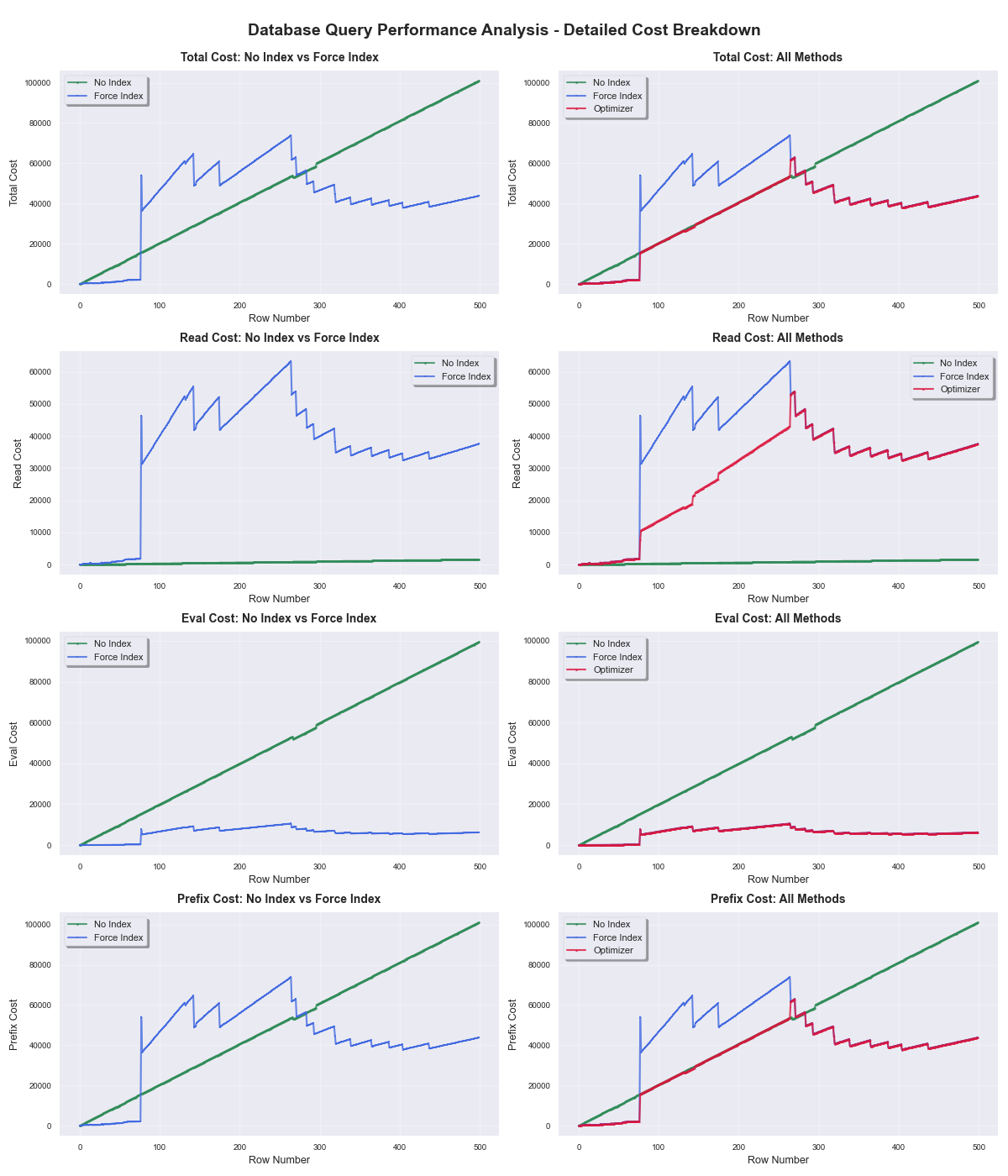
- 공간 인덱스를 사용할 때는
Read Cost가 특정 구간에서 급격히 상승 - 풀스캔은
Eval Cost가 선형 증가. - 두 cost가 교차하는 구간에서
Optimizer가 풀스캔을 선택.
결론적으로 MySQL 5.7의 공간 인덱스는 row 수에 따라 풀스캔이 더 효율적일 수 있다고 판단하는 구간이 존재한다는 걸 확인했습니다
마무리
- 공간 인덱스가 있다고 항상 선택되는 것은 아니다.
Optimizer의cost계산에 따라 풀스캔이 선택될 수 있음. R 테이블의 row 수가 “Optimizer가 풀스캔을 선호하는 구간”에 있었던 게 원인이었음.- 운영에서 비슷한 이슈가 있다면, 당황하지말고 실행계획과
cost를 먼저 살펴보자.
비슷한 경험이나 더 나은 방법이 있다면 댓글이나 메일로 공유해 주시면 감사하겠습니다!
'Database' 카테고리의 다른 글
TABLE SWAP 개선: ALTER TABLE RENAME vs RENAME TABLE (0) 2025.09.05